
What is a web crawler? | How web spiders work

What is a web crawler bot?

Search engine bots download, and index content from all over the Internet. The aim of these bots is to discover what (almost) all web pages are about, so that information can be retrieved when necessary. They are known as “web crawlers” because crawling is the technical term for automatically accessing a website and obtaining data using a software program.
These spiders are always operated by search engines. Data collected by web crawlers and applying to search algorithm search engines can provide relevant links in response to users’ search queries, generating the list of web pages that appears after a user performs a search on Google or Bing (or any other search engine).
A web crawler bot is like someone who goes to a disorganized library and creates a card catalog so that anyone visiting the library can quickly and easily find the information they need. In order to catalog and classify the books in the library by subject, the organizer will have to read the title, abstract and part of the text of each book to discover what it is about.
However, unlike a library, the Internet is not made up of stacks of books, and that makes it difficult to know if all the necessary information has been indexed correctly or if a large amount of information has been gone through. To try to find all the related
information and provide the Internet, a web crawler spider will start with a certain set of known web pages and follow the hyperlinks from those pages to other pages, follow the hyperlinks from those pages to additional pages, and so on. successively.
It is not known how much of the publicly available internet search engine bots get to crawl. Some sources estimate that only 40-70% of the internet is indexed for search – that’s billions of web pages.
What is search indexing?

Search indexing is like creating an Internet library card catalog so that a search engine knows where to retrieve information on the Internet when a person does a search. It can also be compared to the index at the end of a book, which lists all the places in the book where a certain topic or phrase is mentioned.
Indexing focuses on all the text that appears on the page and on the metadata * about the page that users don’t see. Most search engine index pages and add all words on the page to the index When users search for those words, the search engine checks its index of all the pages where those words appear and select the most relevant ones.
* In the context of search indexing, metadata is data that gives information to search engines about what a web page is about. Often times, the meta title and meta description is what will appear on search engine results pages, as opposed to content on the web page that is visible to users.
How do web crawlers work?
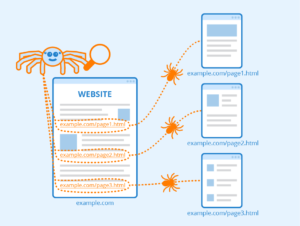
The Internet is always changing and expanding. Since it is not possible to know the total number of web pages on the Internet, web crawler bots start from a seed or a list of known URLs. First of all, they crawl the web pages at those URLs. As they crawl those web pages, they will find hyperlinks to other URLs and add them to the list of pages to crawl later.
Due to the huge number of web pages on the Internet that could be indexed for your search, this process could be running almost indefinitely. However, According to web crawler policies, web crawler ensures is which web pages are crawl and in what order to crawl, and how often they have to be crawled again for content updates.
The relative importance of each web page: most web crawlers do not crawl the entire publicly available internet and that is not their purpose; Instead, they decide which pages to crawl first depending on the number of other pages that link to that page, the number of visitors they receive, and other factors that indicate how likely the page is to contain important information.
The idea is that a web page that is cited by many other web pages and receives many visitors is likely to contain good quality authoritative information, so it is especially important that a search engine has it indexed, just as a library would ensure. have many copies of a book in high demand.
Reconsider, web pages: content on the web is continually updated, deleted, or moved to different locations. Web crawlers will need to revisit the pages periodically to ensure the latest version of the content is indexed.
What kind of web crawler bots are active on the internet?
The bots of the main search engines are known as:
Google: Googlebot actually google have two crawlers, Googlebot Desktop and Googlebot Mobile
Bing: Bingbot
Yandex (Russian search engine): Yandex Bot
Baidu (Chinese search engine): Baidu Spider
Why is it important for bot management to consider web crawling?
Malicious bots can cause a lot of damage, from poor user experiences to server crashes and data theft. However, when blocking malicious bots, it is important that beneficial bots such as web crawlers are allowed to access web properties. Cloudflare Bot Management enables beneficial bots to continue to access websites while mitigating malicious bot traffic . The product maintains a whitelist of good bots , such as web crawlers, automatically updated to ensure that they are not blocked.




